Current Benchmark Coverage
Application Domain Distribution
Complexity Level Distribution
Note: Operation count represents the sum of all visualization operations across all test cases.
Data Type Distribution
Note: A case can have multiple data type tags
Visualization Operation Distribution
Note: A case can have multiple operation tags.
Browse Test Cases
Filter and explore all 108 test cases in the benchmark
Application Domain
Complexity Level
Data Type
Visualization Operation
| Case Name | Application Domain | Data Type | Complexity Level | Visualization Operations |
|---|---|---|---|---|
| Loading test cases... | ||||
Contribute Test Case
Help build a comprehensive benchmark for scientific visualization agents. Contribute a test case by submitting the dataset along with task descriptions and evaluation criteria.
📁 File Upload
Files are uploaded to Firebase Cloud Storage. All submissions are stored securely and will be used for the SciVisAgentBench benchmark.
- Maximum data size: < 5GB per dataset
- Ground truth images: PNG, JPG, TIFF, etc. (minimum 1024x1024 pixels recommended)
- Supported source data formats: VTK, NIfTI, RAW, NRRD, HDF5, etc.
About SciVisAgentBench
What is SciVisAgentBench?
SciVisAgentBench is a comprehensive evaluation framework for scientific data analysis and visualization agents. We aim to transform SciVis agents from experimental tools into reliable scientific instruments through systematic evaluation.
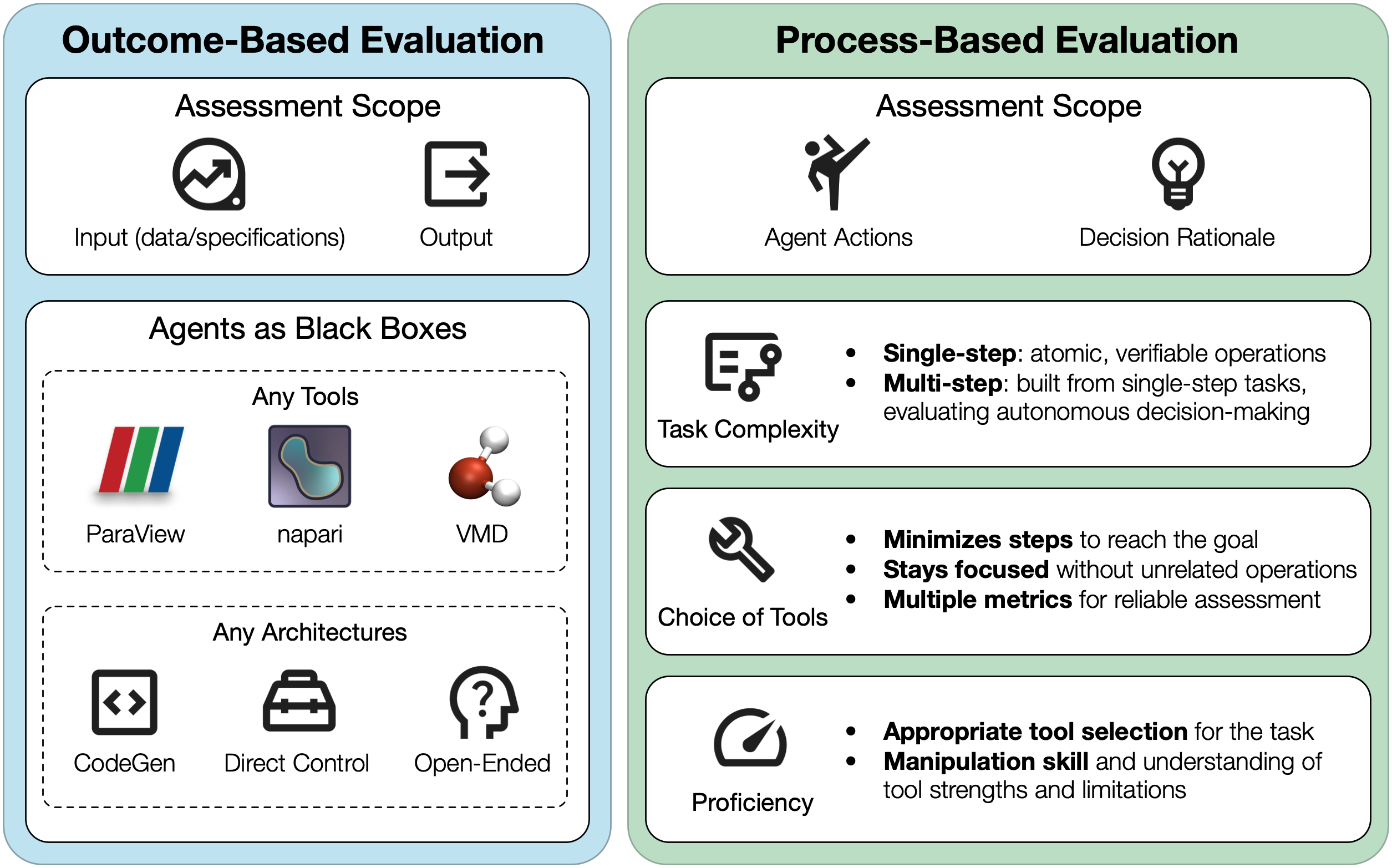
Taxonomy of SciVis agent evaluation, organized into two perspectives: outcome-based evaluation assessing the relationship between input specifications and final outputs while treating agents as black boxes, and process-based evaluation analyzing the agent's action path, decision rationale, and intermediate behaviors.
Why Contribute?
- Help establish standardized evaluation metrics for visualization agents
- Drive innovation in autonomous scientific visualization
- Contribute to open science and reproducible research
- Be recognized as a contributor to this community effort
Evaluation Taxonomy
Our benchmark evaluates agents across multiple dimensions, including outcome quality, process efficiency, and task complexity. We combine LLM-as-a-judge with quantitative metrics for robust assessment.
See our GitHub repository for evaluation examples and deployment guides.
Team
The core team for this project comprises the University of Notre Dame and Lawrence Livermore National Laboratory. Main contributors include Kuangshi Ai (kai@nd.edu), Shusen Liu (liu42@llnl.gov), Kaiyuan Tang (ktang2@nd.edu), and Haichao Miao (miao1@llnl.gov).
Contributors
We are grateful to all contributors who have helped build this benchmark.
| Contributor | Institution | # of Questions | Subjects |
|---|---|---|---|
| No contributions yet. Be the first to contribute! | |||